Il mondo dello sviluppo software sta assistendo ad alcuni cambiamenti fondamentali con la rinascita di varie tecniche di intelligenza artificiale. L'impatto più significativo si è avuto sotto forma di Machine Learning e, più specificamente, di un sottoinsieme di ML chiamato Deep Learning. Il ML è semplicemente una forma di AI che consente a un sistema di "imparare" o essere "addestrato" dai dati piuttosto che da una programmazione esplicita. È importante notare che queste tecniche non sono nuove. Il termine AI è stato coniato per la prima volta da John McCarthy nel 1956 ed è definito come la capacità di una macchina di imitare il comportamento umano intelligente. Questo non deve essere confuso con una macchina dotata di effettiva intelligenza o in grado di imitare genericamente un essere umano. I sistemi di intelligenza artificiale sono progettati per imitare specifiche capacità umane. Ad esempio: comprendere il linguaggio, risolvere problemi specifici, riconoscere suoni/immagini e classificarli, fare previsioni, ecc. Ognuna di queste capacità è molto potente, ma non riflette l'intelligenza "reale".
Nel corso degli anni sono stati studiati diversi tipi di IA, la maggior parte dei quali è passata in secondo piano, mentre l'apprendimento automatico ha trovato la sua rinascita. Negli anni '90, le due sottocategorie di IA più studiate erano il ML e i sistemi esperti. I sistemi esperti sono una tecnica in cui un sistema viene programmato con un insieme di regole piuttosto che essere esplicitamente codificato. Le regole venivano elaborate da un "motore di regole/inferenza" e potevano gestire decine di migliaia di eventi al secondo anche su hardware modesto. Il problema è che le regole vere e proprie dovevano essere definite da esperti in materia ed erano limitate dalla capacità delle PMI di individuare tutte le situazioni potenziali possibili. In realtà, non si tratta di IA, ma di una sua approssimazione.
L'apprendimento automatico, invece, è una tecnica in cui il software (modello) impara dai dati piuttosto che essere creato/codificato o definito dagli sviluppatori di software. La tecnica specifica di ML che descrivo in questo documento è nota come Deep Learning o Reti neurali. Vorrei sottolineare che questa tecnica NON è nuova ed è stata sviluppata originariamente negli anni '60, '70 e '80. Infatti, la svolta che ha reso utilizzabili le reti neurali è stata chiamata propagazione all'indietro e scoperta/pubblicata nel 1986. Sfortunatamente, sebbene le tecniche fondamentali per implementare le reti neurali fossero ben comprese, all'epoca non erano effettivamente utili a causa delle enormi risorse di elaborazione e delle dimensioni dei set di dati necessari per addestrare le reti. L'unica soluzione commerciale che mi viene in mente era un prodotto di Computer Associates degli anni '90, chiamato Neugents (parte della suite di gestione dei sistemi). Le reti neurali sono state abbandonate dal settore commerciale e dalla maggior parte del mondo accademico; solo alcune università continuano a fare ricerca in questo campo, soprattutto qui in Canada.
Torniamo alle reti neurali, che in realtà non sono affatto complicate.
Partendo dalle basi, una rete neurale è un insieme di neuroni uniti in strati a cascata. La rete inizia con uno strato di ingresso, passa attraverso strati nascosti e i risultati passano infine attraverso lo strato di uscita. Prima di addentrarci nei dettagli di questa struttura, dobbiamo iniziare a capire cosa si intende per neurone (non intendiamo una vera e propria cellula vivente).
Un neurone è un elemento di calcolo che riceve più input e calcola un singolo output. Ecco un semplice esempio:
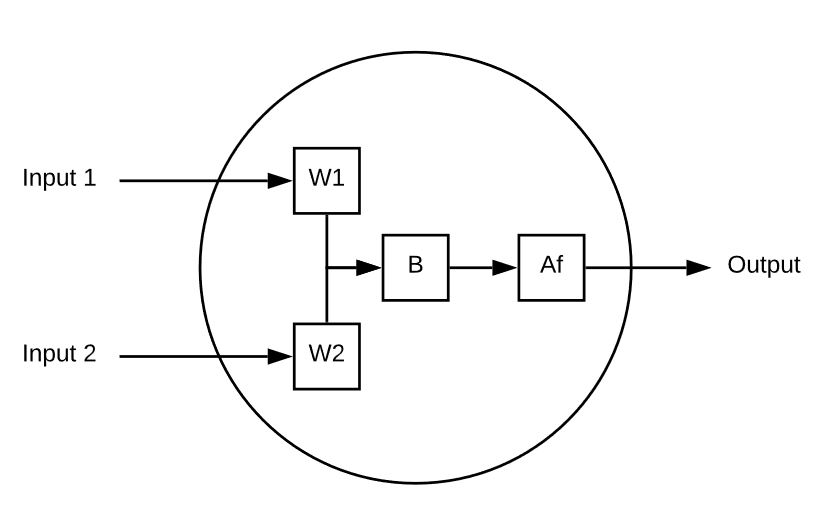
Questo neurone ha 2 ingressi.
Ogni ingresso è moltiplicato per il peso.
Gli ingressi ponderati vengono poi sommati e a questi viene aggiunto un valore di bias.
Infine, il valore non limitato viene passato attraverso una funzione di attivazione (ad esempio, sigmoide) per ridurlo a un intervallo prevedibile (ad esempio, da 0 a 1).
Ecco un esempio di un singolo neurone in azione:
Ingresso 1 = 5, Ingresso 2 = 8, W1 = 1 e W2 = .5, infine il nostro Bias è 3
Il nostro output si presenta come segue
Af( ( ( 5 * 1 ) + ( 8 * .5 ) + 3 )
Af( 12 ) = 0,999
Riproviamo con una serie diversa di input, pesi e bias:
Ingresso 1 = 10, Ingresso 2 = 10, W1 = 0,2, W2 = 0,1, Bias = 0,5
Uscita = Af( (-10 + 0,2) + ( 2 X 0,1) + 0,5)
Uscita = Af( -8,1 ) = 3,034
Un singolo neurone da solo è essenzialmente inutile, se non come interessante esercizio matematico, ma se mettiamo insieme più neuroni in strati possiamo avere una rete neurale nella forma di:
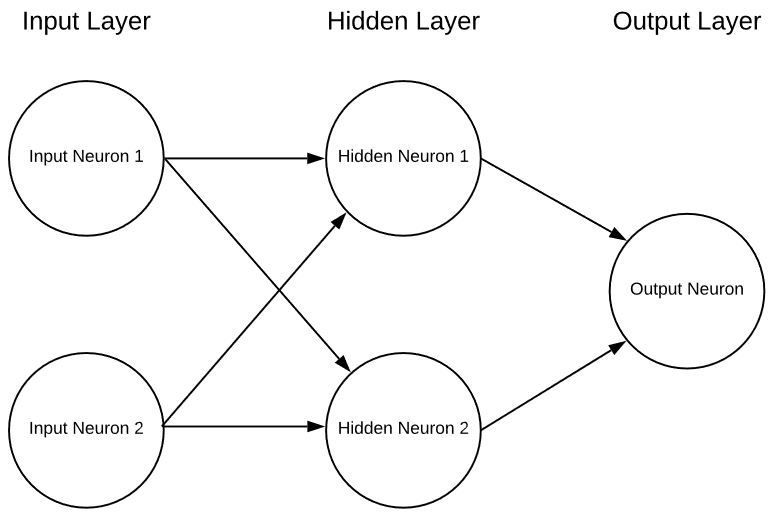
Questa è una rete neurale estremamente semplicistica con 2 ingressi, un singolo strato nascosto di neuroni e infine un singolo neurone di uscita. Le reti neurali possono avere un numero qualsiasi di ingressi, di strati e di neuroni in questi strati. Questa flessibilità è l'unico problema serio delle reti neurali. Come fa il progettista della rete a sapere qual è il numero ottimale di strati e di neuroni al loro interno? Esistono alcune linee guida da cui partire, ma la realtà è che per capirlo bisogna andare per tentativi. Attualmente sono in corso molte ricerche molto promettenti per aiutare in questo senso, ma stiamo appena iniziando a capire questa parte.
Come si scelgono i pesi e le polarizzazioni giuste per ogni neurone e come si "impara"?
Un ottimo argomento per la prossima puntata.